



Como priorizar atividades no CS (e em qualquer área)
Um algoritmo para te ajudar a escolher quais coisas fazer primeiro

Antes de mais nada…
Já se inscreveu na lista de espera do meu livro sobre Customer Success?
Eu estou escrevendo um livro falando sobre CS na prática, do jeito brasileiro. Sem idealizações, como fazer funcionar o Sucesso do Cliente em um cenário de clientes de ticket menor e em alto volume. Gostou da premissa? Inscreva-se para receber todas as atualizações sobre a escrita até o lançamento do livro.
A rotina do CS tem muitas prioridades. O CSM precisa segurar churn, expandir contratos, renovar clientes, fazer cross-sell… Uma infinidade de coisas. E tudo ao mesmo tempo.
Equilibrar essas demandas pode ser difícil. E durante muito tempo eu pensei em como responder a pergunta:
Com tantas possíveis coisas para fazer, qual a rotina perfeita para um(a) CSM de acordo com a carteira que ele(a) tem?
Até que um dia eu cheguei na resposta: um algoritmo. Uma equação.
Não sei se vocês sabem, mas eu sou um nerd de carteirinha. Acho que já deu para perceber pelas planilhas que eu gosto bastante de números. Mas vocês não fazem ideia do quanto.
Eu me interesso por algoritmos (programo há 14 anos, principalmente linguagens matemáticas como MATLAB, R, Python, etc), estatística, probabilidade, aprendizado de máquina… Para vocês terem noção, eu estudei Engenharia Mecânica e meu TCC foi uma simulação numérica de um túnel de vento, em que eu simulei o ar dentro do tubo como uma matriz de 625x625x625. Era um algoritmo que levava horas para rodar.
Até hoje eu estudo algumas coisas assim por diversão. Eu realmente gosto. E foi durante esses estudos aleatórios que eu cheguei a algumas respostas sobre a rotina do CS.
Esse artigo provavelmente não será muito popular. Ele pode ser um pouco complexo. E peço desculpas por isso. Mas eu me orgulho muito dessa teoria e pretendo publicá-la ou produtizá-la algum dia. É o tipo de trabalho que rende uma patente. Se você gostar da teoria e pensar em formas de evoluir, vamos conversar sobre ela!
É uma teoria porque eu ainda não consegui testá-la. Isso por causa da falta de tempo e da estrutura de dados necessária, que eu demorei a conseguir ter. Hoje eu até tenho as condições para testar, mas falta tempo para dedicar ao projeto de pesquisa. Até por isso eu não tenho medo de falar abertamente sobre o algoritmo aqui.
Vou contar todo o processo para chegar no algoritmo e tudo que você precisaria para tirar do papel. Se você conseguir implementar por aí, me conte. E não esqueça de me referenciar, claro!
A dedução da fórmula
Por uns dois anos, eu e meu antigo líder discutimos como deveria ser a rotina de um CSM. Ele era um cara mega pragmático e, por isso, nos demos muito bem. Ele era um diretor que olhava para toda a estrutura de Go-To-Market (Marketing, Vendas e CS).
Ele tinha uma visão super interessante, ele dizia:
“Na minha opinião, o CS deveria começar o dia dele, abrir o Hubspot e as atividades sugeridas estarem lá.”
Basicamente o que ele sugeria é que houvesse um algoritmo de priorização capaz de sugerir as “melhores” atividades para o time de CS. E durante muito tempo eu pensei como tornar isso real.
Até que certo dia, eu estava lendo um livro - eu queria muito lembrar qual era para referenciar aqui - que falava sobre como priorizar investimento em projetos. Esse livro trazia uma fórmula para essa priorização, que me deu um estalo. A fórmula basicamente era:
Retorno Esperado = Probabilidade de Retorno × Valor do Retorno
Eu li essa equação e na hora me acendeu uma luz. Eu imaginei cada ação do CS como um desses possíveis investimentos. Afinal, é isso mesmo. Você está investindo tempo e um recurso buscando um retorno. Agora imagine a seguinte situação:
Seu CSM quer tentar fazer um upsell em um cliente. Digamos que esse upsell é de R$ 300,00 por mês e o tempo estimado que um cliente permanece com você após um upsell é de mais 12 meses. Se seu CSM tem 30% de chance de conseguir um upsell, o retorno esperado daquela ação é de 0,3 (30%) x R$ 300,00 x 12 = R$ 1080,00.
Na época pensei:
“Poxa, se cada atividade tem um retorno financeiro esperado, para priorizar as atividades bastaria classificar pelo maior retorno e começar a atuar nelas da maior para a menor.”
Talvez você esteja se perguntando: como é medido o retorno estimado no caso de uma ação de reversão de churn? É simples. O retorno é a receita daquele cliente. Afinal de contas, o retorno daquela ação é a receita ficar. O retorno de não agir, é perder aquele dinheiro. A complexidade nos casos de churn é estimar as probabilidades de cada cliente sair. Recomendo aqui que você use uma curva de churn levantada a partir de análises de cohort, combinado com algum algoritmo que dê um peso a mais ou a menos de acordo com o comportamento atual do cliente. Isso caso você não tenha já um Health Score que dê o percentual diretamente.
Com isso, cheguei até a montar um algoritmo que fazia essa classificação com todas as possíveis atividades do CS. Ele funcionava. E funcionava razoavelmente bem. Bem o suficiente para ser implementado na maioria das operações até.
Mas aí percebi uma simplificação perigosa:
Eu estava considerando que todas as atividades levavam o mesmo tempo a serem feitas. O que está longe de ser verdade.
Então, comecei a elaborar um pouco mais a teoria. Se você juntar a equação do retorno com a lógica de ROI (retorno sob investimento), o ROI de uma atividade - como o upsell do exemplo - é basicamente o retorno estimado dividido pelo tempo para fazer aquilo (ou o equivalente em reais do salário do CS nas horas dedicadas).
Agora imagine que entre planejamento, contato com cliente, follow-up e operacionalização do upsell, seu CS gastou cerca de 4 horas nesse negócio.
Se o CSM tem um salário bruto próximo de R$ 4 mil reais, multiplicando por 1.7 dá um custo mensal aproximado de R$ 6,8 mil. Dividindo por aproximadamente 176 horas de trabalho em um mês, chega-se a um custo de R$ 38,64 por hora. Então, esse upsell “custou” R$ 154,54 a ser feito.
Faltaria ainda calcular o custo de oportunidade. Afinal de contas, para fazer esse upsell, o CS perdeu a oportunidade de estar fazendo outra atividade que poderia até trazer mais retorno. Mas para fins didáticos, não vamos aprofundar nisso por aqui.
Então, o ROI do upsell do exemplo seria:
Retorno / Investimento = R$ 1080/154,54 = 6,99
Um excelente ROI.
Isso me fez pensar um pouco mais. Logo eu cheguei à seguinte conclusão:
Então, para chegar à rotina ideal de um CSM, bastaria eu otimizar o somatório de ROI esperado de um dia de trabalho. Acabei chegando então à equação:
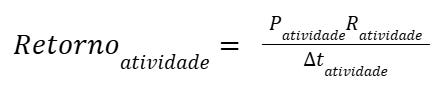
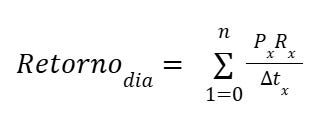
Onde:
Px = Probabilidade de sucesso da atividade x
Rx = Retorno potencial da atividade x
delta t = Tempo para realizar a atividade x
Ou seja:
O retorno estimado de uma atividade é igual à probabilidade de sucesso daquela atividade, multiplicado pelo retorno do sucesso, dividido pelo delta de tempo para realizá-la. Sendo assim, o retorno de um dia de trabalho perfeito é igual ao somatório das melhores atividades possíveis, até o limite de tempo de um dia.
Teoricamente, bastaria listar todas as possíveis atividades de um CSM e classificar do maior para o menor retorno. Quando chegasse ao limite de tempo de um dia, “cortaríamos” a sugestão.
Mas aí, o algoritmo começou a ficar complexo e eu acabei engavetando ele. Por mais que a equação seja relativamente simples, conseguir estimar cada uma das variáveis não é. Vou falar mais sobre isso no final do artigo.
Até que um dia eu estava fazendo um curso, que me reacendeu a ideia do algoritmo. Eu estava fazendo o curso “Pesquisa Operacional (1): Modelos e aplicações” da Coursera, quando me deparei com um problema matemático que segundo eles, é famoso: o Knapsack problem (ou problema da mochila, em tradução literal).
O problema da mochila é um problema clássico de otimização combinatória. Ele é mais ou menos assim:
“Você vai acampar e precisa preparar uma mochila. Você tem uma mochila que tem um limite de peso de 15kg e tem uma variedade de itens possíveis de serem colocados na mochila. Cada item tem um peso e um “valor”. Você precisa escolher os itens de forma que maximize o valor, dado o limite de peso.”
Descobri também que esse tipo de problema tem nome: chama-se Programação Linear.
Quase que instantaneamente eu percebi que se trata de um problema análogo ao da priorização do CS, onde:
O “valor” é o impacto
O “peso” é o tempo
Portanto, a equação de priorização de atividades do CS considerando o que descobrimos lá atrás e o que diz o problema da mochila, seria:

Resolvendo essa equação numérica você conseguiria determinar quais as melhores atividades para o CSM em um determinado dia de trabalho.
Há diversas maneiras de resolver um problema como este, desde força bruta até algoritmos avançados. Na página da Wikipédia que ensina sobre o Knapsack Problem, há várias possíveis formas de solução.
Complexidades
Algum dia eu ainda pretendo “empacotar” isso em uma solução plug-and-play. Um produto para ser implementado facilmente em qualquer operação de CS. Mas ainda não consegui pensar em uma forma simples de fazer isso, por vários motivos:
Você precisa de processos bem desenhados, que mensurem as probabilidades de cada tipo de atividade acontecer (isso pode ser mensurado, por exemplo, com pipelines no seu CRM).
Você precisa de dados que ajudem a estimar o tempo de cada atividade. Para isso, você precisa de uma forma de registro de atividades. Se você tiver as atividades de cada tipo por dia já dá. Não precisaria nem de quanto tempo a atividade “durou”, você consegue estimar esse tempo médio usando álgebra linear.
Você precisa de boas estimativas de retorno de cada tipo de atividade. No caso de um up-sell ou cross-sell isso é simples. Mas no caso de uma ação de relacionamento ou treinamento, por exemplo, você precisaria de dados que dissessem o quanto aquilo contribui para a fidelização e assim estimar o retorno financeiro daquilo.
Mesmo nas ações de up-sell e cross-sell, às vezes é difícil determinar com precisão a receita potencial de um cliente em um negócio, dadas as inúmeras possíveis variáveis de precificação.
A “probabilidade” de uma ação de churn é difícil de estimar e está muito ligada à qualidade do Health Score que você criou. Se você tem um health score que não mede probabilidade de forma percentual, fica difícil estimar essa probabilidade para medir o retorno esperado.
A probabilidade de fechamento de um negócio depende de fatores como a satisfação atual do cliente ou se o cliente é ou não ICP para um determinado cross-sell. Portanto, pode ser necessário um algoritmo de “lead scoring” para determinar também a probabilidade de fechamento de negócio por produto.
Você pode decidir pelo tipo de atividade mais indicada para cada cliente de acordo com o estágio do ciclo de vida dele. Para isso, você precisa de uma boa lógica de classificação do cliente na jornada. Eu geralmente classifico os clientes entre “onboarding”, “expansão”, “renovação”, “risco” e “promoção”.
Quando você listar as possíveis atividades, pode ser que mais de uma atividade de altíssimo valor seja em um mesmo cliente. Talvez faça sentido você “agrupar por cliente” as atividades e somar o impacto, para determinar quais clientes são mais importantes de serem contatados no momento.
A estratégia da empresa pode impactar no “peso” das atividades. Caso se trate de uma empresa com muito foco na experiência do cliente, o peso de ações de proximidade com o cliente pode ser desproporcionalmente maior. Algo que é difícil de estimar, às vezes. Outro exemplo disso é quando você tem um produto maduro, de churn baixo e que acredita muito na estratégia do Landing & Expanding. Nesses casos, ações de expansão são mais relevantes também.
Tudo isso faz com que esse algoritmo precise de um tanto de trabalho para ser implementado em uma operação. Seja de captura de dados ou mesmo de adaptação ao cenário do negócio.
Como “criador” disso, eu ainda penso em criar uma metodologia de implementação. Quem sabe um dia.
Simplificações a aproximações
Apesar de todas as dificuldades, há formas de você usar esse algoritmo de maneira simplificada.
Isso é bastante comum na matemática e na física. Uma das equações mais úteis do mundo é uma equação “impossível” de solucionar, e que é utilizada com um monte de “simplificações”. Eu estou falando da equação de Navier-Stokes. Eu usei ela no meu TCC. Inclusive, quem conseguir demonstrar uma solução “suave” para ela, ganha US$ 1 milhão da Clay Mathematics Institute por ser um dos chamados “Problemas do Milênio”.
Como fazer essas simplificações?
Você pode considerar cada tipo de atividade com uma probabilidade arbitrária (também conhecida como “chutada”): você pode definir, por exemplo, que toda tentativa de upsell deveria ter 30% de conversão e usar isso como “meta” de desempenho do time.
Você pode desconsiderar o tempo: você pode dizer que todas as atividades tomam em média o mesmo tempo ou usar médias de tempo por tipo de atividade (novamente de forma “arbitrária”).
Você pode usar o algoritmo apenas para priorizar ações de expansão e churn: assim você tem as sugestões de ações de controle de churn e de ações de expansão baseadas no algoritmo e as ações de “relacionamento” mais baseadas na necessidade do dia a dia.
Passo a passo de implementação
Liste todos os seus clientes
Calcule para cada cliente o impacto de cada tipo de atividade (reversão de churn, up-sell, cross-sell…), desconsidere inicialmente o tempo e coloque conversões arbitrárias (ex: 50% de chance de reter o churn ou 30% de chance de converter uma expansão).
Classifique cada cliente de acordo com o ciclo de vida e defina a atividade mais indicada. Clientes em risco = atividade de retenção, clientes em expansão = atividades de negócios.
Classifique o potencial de cada atividade ou cliente do maior para o menor
Pegue o top 5 ou 10 (o que couber na sua rotina) e atue neles para o dia ou faça semanalmente um recorte de 20 a 50 tarefas sugeridas.
Depois disso, melhore o algoritmo:
Inserindo as conversões reais de cada produto e tipo de cliente. Crie o algoritmo de lead scoring de acordo com esses fatores.
Inserindo a probabilidade mais assertiva de risco vinda do Health Score de acordo com fatores como maturidade, comportamento e características gerais do cliente.
Torne o algoritmo mais personalizado para cada CSM, usando as probabilidades de reversão e conversão de cada um. Isso dará uma lista muito mais direcionada às habilidades do dono de cada carteira.
Use o algoritmo do problema da mochila para sugerir as atividades sem um número fixo, mas com um valor mais real do que é possível fazer no dia.
Insira pesos em cada tipo de atividade de acordo com critérios estratégicos do negócio.
Você já respondeu à Customer Report Brasil?

Tá rolando a maior pesquisa sobre o mercado de atendimento ao cliente no Brasil. Ajude a construir os benchmarks nacionais e tenha acesso aos dados e ganhe prêmios!
Não consegui acompanhar no detalhe as fórmulas, mas achei genial vc trazer a matemática nesse tema de gestão de prioridades.
Tem sido a dor do meu time no momento priorizar atividades.
A lógica que estou usando é de MRR:
- Se tem 1 Churn, 1 Up, 1 cross, 1 renovação, 1 Ticket de atendimento pra fazer, olha quem gera maior MRR e comece por ela e siga sucesivamente em ordem descrecente de MRR as demais.
É simples e com certeza deve ter ponto cego.
Mas, está funcionando por enquanto.